CDA“不靠谱”的预测 今年双十一的销量是6213亿元!
扫一扫
分享文章到微信

扫一扫
关注99科技网微信公众号
原标题: CDA“不靠谱”的预测 今年双十一的销量是6213亿元!
双十一到今年已经是13个年头,每年大家都在满心期待看着屏幕上的数字跳动,年年打破记录。而 2019 年的天猫双11的销售额却被一位微博网友提前7个月用数据拟合的方法预测出来了。他的预测值是2675.37或者2689.00亿元,而实际成交额是2684亿元。只差了5亿元,误差率只有千分之一。今儿我们特邀了CDA数据分析师的明星小导师曹鑫老师,也来做一个“不靠谱”的预测。
但如果你用同样的方法去做预测2020年的时候,发现,预测是3282亿,实际却到了 4982亿。原来2020改了规则,实际上统计的是11月1到11日的销量,理论上已经不能和历史数据合并预测,但咱们就为了图个乐,主要是为了练习一下 Python 的多项式回归和可视化绘图。
把预测先发出来:今年双十一的销量是 9029.688 亿元!坐等双十一,各位看官回来打我的脸。
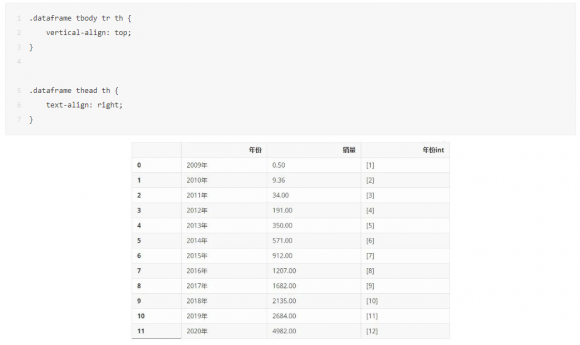
NO.01统计历年双十一销量数据
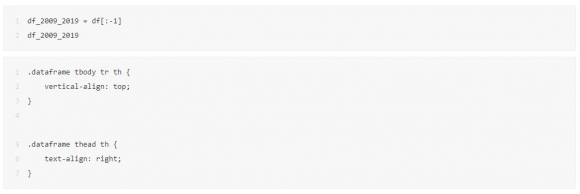
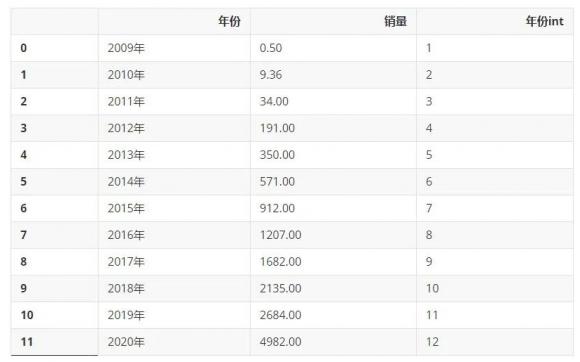
从网上搜集来历年淘宝天猫双十一销售额数据,单位为亿元,利用 Pandas 整理成 Dataframe,又添加了一列'年份int',留作后续的计算使用。

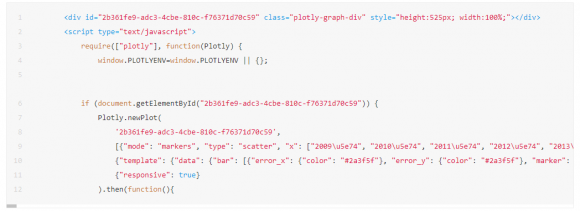
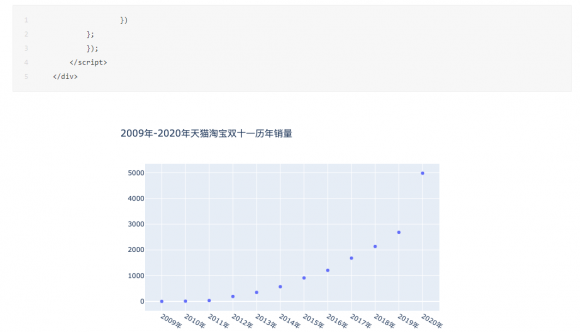
NO.01绘制散点图
利用 plotly 工具包,将年份对应销售量的散点图绘制出来,可以明显看到2020年的数据立马飙升。


NO.03引入 Scikit-Learn 库搭建模型
一元多次线性回归
我们先来回顾一下2009-2019年的数据多么美妙。先只选取2009-2019年的数据:
通过以下代码生成二次项数据:

1.第一行代码引入用于增加一个多次项内容的模块 PolynomialFeatures
2.第二行代码设置 次项为二次项,为生成二次项数据(x平方)做准备
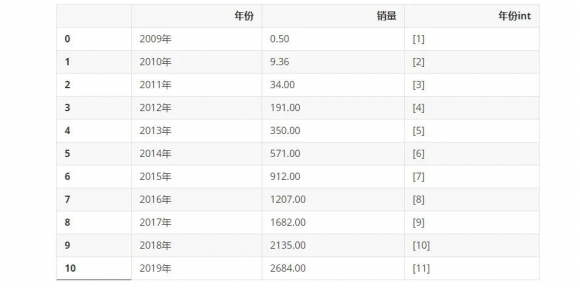
3.第三行代码将原有的X转换为一个新的二维数组X_,该二维数据包含新生成的二次项数据(x平方)和原有的一次项数据(x)
X_ 的内容为下方代码所示的一个二维数组,其中第一列数据为常数项(其实就是X的0次方),没有特殊含义,对分析结果不会产生影响;第二列数据为原有的一次项数据(x);第三列数据为新生成的二次项数据(x的平方)。
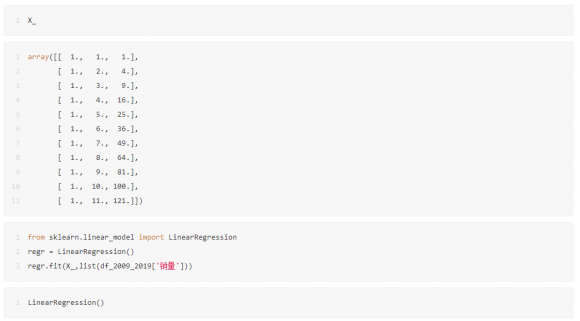
1.第一行代码从 Scikit-Learn 库引入线性回归的相关模块 LinearRegression;
2.第二行代码构造一个初始的线性回归模型并命名为 regr;
第三行代码用fit() 函数完成模型搭建,此时的regr就是一个搭建好的线性回归模型。
NO.04模型预测
接下来就可以利用搭建好的模型 regr 来预测数据。加上自变量是12,那么使用 predict() 函数就能预测对应的因变量有,代码如下:
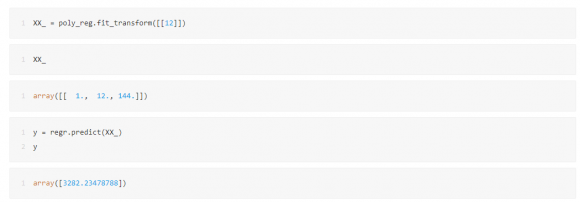
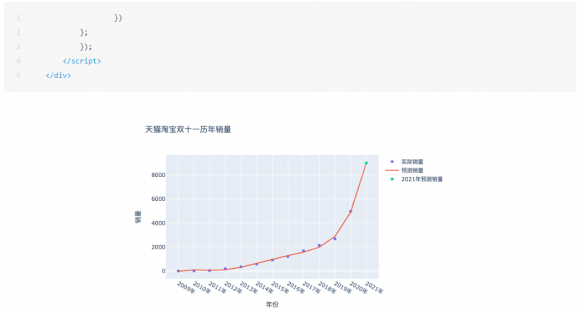
这里CDA数据分析师就得到了如果按照这个趋势2009-2019的趋势预测2020的结果,就是3282,但实际却是4982亿,原因就是上文提到的合并计算了,金额一下子变大了,绘制成图,就是下面这样:

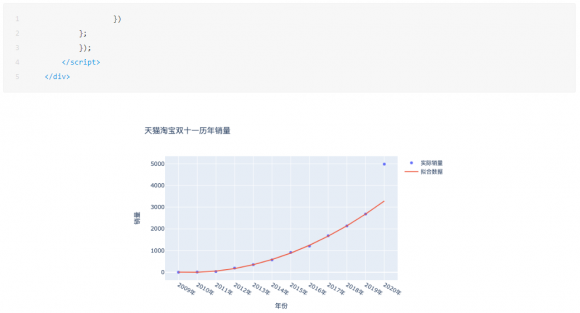
NO.05预测2021年的销量
既然数据发生了巨大的偏离,咱们也别深究了,就大力出奇迹。同样的方法,CDA数据分析师曹鑫老师把2020年的真实数据纳入进来,二话不说拟合一样,看看会得到什么结果:




NO.06多项式预测的次数到底如何选择
在选择模型中的次数方面,可以通过设置程序,循环计算各个次数下预测误差,然后再根据结果反选参数。

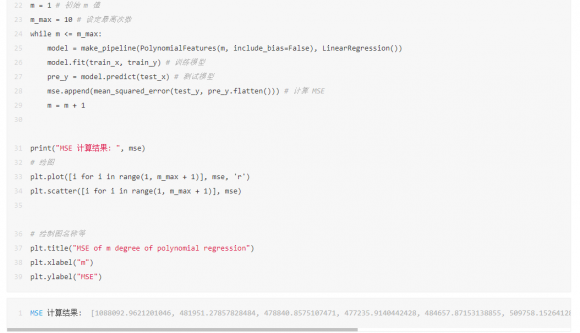
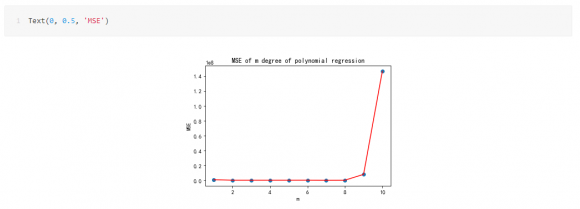
从误差结果可以看到,次数取2到8误差基本稳定,没有明显的减少了,但其实你试试就知道,次数选择3的时候,预测的销量是6213亿元,次数选择5的时候,预测的销量是9029亿元,对于销售量来说,这个范围已经够大的了。我也就斗胆猜到9029亿元,我的胆量也就预测到这里了,破万亿就太夸张了,欢迎胆子大的同学留下你们的预测结果,让我们11月11日,拭目以待吧。
NO.07总结最后
希望CDA数据分析师曹鑫老师的这篇文章带着对 Python 的多项式回归和 Plotly可视化绘图还不熟悉的同学一起练习一下。想要完整代码的同学,可以搜我。
投稿邮箱:jiujiukejiwang@163.com 详情访问99科技网:http://www.fun99.cn