“百模大战”价格战打响 互联网大厂让利“引爆”市场
扫一扫
分享文章到微信

扫一扫
关注99科技网微信公众号
原标题:“百模大战”价格战打响 互联网大厂让利“引爆”市场
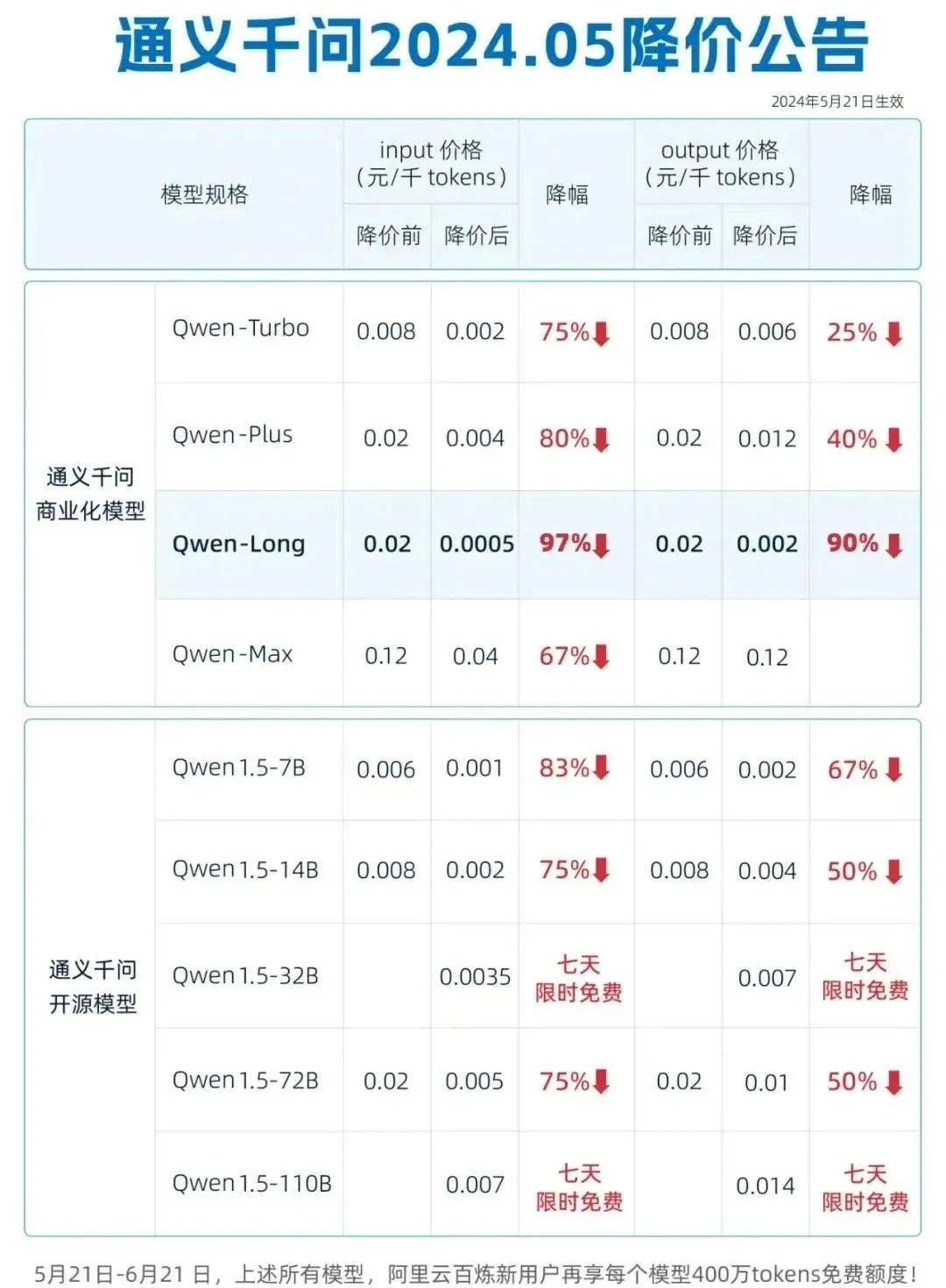
最近,国内大模型领域掀起了一波降价潮,字节跳动的豆包通用模型pro-32k版输入价格定价0.0008元/千tokens后,阿里云旗下的通义千问立马宣布将Qwen-Long的输入价格从0.02元/千tokens降至0.0005元/千tokens。
没有最低,只有更低。如今腾讯、科大讯飞等头部玩家都已经加入这场降价大作战中。
2023年国内大模型赛道进入创业高峰期,一年不到,整个市场又马不停蹄步入洗牌期。亏钱换市场这套屡见不鲜的打法确实是不可持续的,但也是每波互联网浪潮下大厂们卡风口必不可少的战术。
只是如今的“百模大战”与此前的“千团大战“”千播大战”等还是有所不同的。大模型厂商们不断击穿底价背后,固然有争夺市场份额的考量,但也是在通过降低下游企业的应用成本来推动大模型市场的提前爆发。
“百模大战”必将打响
2023年年初百度、阿里、腾讯等头部互联网企业陆续推出自家的大模型后,国内大模型市场就开始进入狂飙期,2023年第二季度开始几乎每个月都有多款大模型发布。截至2024年年初,国内大模型数量已经超过300个,市场规模突破100亿元,且未来仍将持续高速增长。
具体来看,如今国内通用大模型数量达到40个左右,但仅有四分之一出圈度较高,比如百度的文心一言、字节跳动的豆包大模型、科大讯飞的星火模型、阿里巴巴的通义千问、腾讯的混元大模型、华为的盘古大模型、百川智能的百川大模型等。在应用侧,这些通用大模型的B端市场正在一步步打开,但C端市场感知度仍稍欠火候。
比如在APP Store应用排行榜TOP100行列中,目前只有发力较早的文心一言的身影,即便将范围放宽到TOP200也很难看到其他上榜的通用大模型,在部分深度用户群体中,影响力较高也几乎都是上述头部大模型。仅看C端市场的话,在“百模大战”打响之前,行业就已经呈现出第一梯队的头部企业与明星产品同台竞技的竞争格局了。
不仅是通用大模型,过去一年来垂直大模型也卷疯了,金融、教育、医疗、文娱传媒、企业服务、零售、制造业等多个领域的垂直大模型竞争都在白热化。比如金融领域就相继出现了蚂蚁金融、LightGPT、天镜、麒麟、泛海言道、轩辕等数十款大模型,背后站着的则是马上消费、蚂蚁集团、东方财富证券、度小满等企业。

图源:亿欧智库
在文娱领域,中央广播电视台、抖音、知乎、阅文集团、掌阅等多家外界较为熟悉的文娱企业都进入了大模型赛道。整体来看,现阶段大模型在金融、教育、文娱传媒等垂直赛道的落地步伐更快,比如在影视内容的生产上,早在今年三月份央视频便发布了首部AI全流程微短剧《中国神话》。
大模型服务商零一万物创始人李开复接受媒体采访时表示,大模型的疯狂降价是一种双输的不理智策略,如果技术不达标,仅仅依靠赔钱做生意是不可持续的,零一万物也绝对不会跟这样的定价来做对标。但问题在于,通用赛道和垂类赛道都如此拥挤的大背景下,通过价格战让市场提前进入洗牌期几乎是必然趋势,因为谁都耗不起。
对大模型这一高资源投入、高成本、高人才密集度的领域而言,竞争格局未定之前,比起追求极致的技术,先活下来才是最重要的。因此现阶段整个大模型市场更需要先从野蛮生长期快速步入产业整合期,等市场集中度达到一定程度后,再去谈更为精细化的行业洗牌。
况且,如今大模型行业所面临的“有限算力”问题也未得到解决。亿欧智库在《2024中国“百模大战”竞争格局分析报告》给出了一组数据:据工业和信息化部预测,2023年年底国内将有5%至8%的企业大模型参数从千亿级跃升至万亿级,算力需求增速会达到320%,而国内智能算力规模在2023年至2027年的复合年均增长率仅为28.2%。
在2023年的中国计算机大会上,中国通信学会副理事长徐文伟表示只有芯片、应用、架构等系统全域协同优化,才能有效解决算力提升问题,也就是说,在算力供给问题解决之前,大模型市场维持现有规模高速向前迈进是不现实的。无论从何种角度来看,疯狂卷都是整个市场避不开的命运。
不过,抵制价格战的李开复也为自己预留了退路,即如果以后国内大模型市场还是如此卷,那零一万物就走国际化路线。但就目前的形势来看,国内卷不赢国外更走不通,且不说OpenAI在海外影响力一骑绝尘,就资本竞争来看,谷歌、亚马逊等诸多头部互联网公司也在大模型领域打得如火朝天,想要突围并非易事。
以让利推动市场爆发
大模型价格战打响后,相关新闻中高频出现的“免费”“底价”“平价时代”等字眼,所营造出的氛围似乎是“所有大模型厂商都在无脑烧钱换市场”,但事实并非如此。观察全球大模型行业的发展现状,以及字节跳动、百度、阿里等此次价格战的领头玩家所制定的详细降价策略,便会发现由价格战掀起的“百模大战”与以往其他风口的花式大战还是有所区别的。
首先,降价是全球大模型市场的共同趋势,海外市场同样也在卷价格。去年至今,OpenAI多次下调价格,今年GPT-4o输入价格下调到了0.0005美元/千tokens,输出价格下调到了0.0015美元/千tokens,降价幅度分别为83%和75%。为了应对OpenAI的多波降价,去年谷歌的Gemini模型也在疯狂降价。
今年年初,OpenAI CEO萨姆·奥尔特曼与比尔·盖茨在播客节目中探讨AI的发展与未来时曾表示,如今AI技术正处于一个非常陡峭的成长曲线上,成本也在飞快地下降。在日前的微软发布会上,微软CEO萨提亚·纳德拉透露,过去一年GPT-4o的性能提升了6倍,但生成的成本降低了12倍。
近一两年,国内外的大模型厂商都在想方设法从降低训练成本、提高推理性能等多维度入手压缩大模型成本,比如盘古大模型就在去年尝试采用稀疏加稠密架构来降低训练成本。这也是海内外集体卷价格的一大背景,长期来看,作为技术驱动型行业,随着技术的持续升级,未来大模型的算力成本仍有望优化。

其次,大模型厂商的降价策略也大有门道。以阿里的通义千问为例,Qwen-Turbo、Qwen-Plus、Qwen-Long、Qwen-Max四大商业化模型的输出价格中,Qwen-Long降价幅度达到90%,Qwen-Turbo和Qwen-Plus降价幅度分别为25%和40%,Qwen-Max价格保持不变,而Qwen-Max正是Qwen系列中参数规模最大的模型。
旗舰大模型价格稳如泰山的并非阿里一家,比如百度宣布输入与输出双免费的ERNIESpeed、ERNIELite都是今年才推出的轻量级大模型,李彦宏曾在2024百度AI开发者大会上表示,这几款轻量级模型在一些特定场景的使用效果可以媲美大模型。目前,百度文心大模型的旗舰系列ERNIE3.5和4.0价格并非发生变动。
这几乎是头部玩家的通用打法,腾讯的混元-Pro输出价格同样保持不变,大模型本就是“碎钞机”,未来一段时间,“百模大战”中各家成本最高的大模型价格都很难大跳水。由此可见,大模型价格战中厂商们确实在让利应用端,但底层逻辑之一仍是通过低价或免费的基础款产品吸引客户,从而为旗舰产品的长线发展蓄水。
除了为旗舰大模型蓄水外,价格战指向的也是通过低价策略推动大模型应用市场的提前爆发。如今,多数企业正处于AI转型的关口,从亿欧智库报告提到的数据来看,2023年国内已经有一半以上的企业开始了AI相关尝试,其中34%的企业正在做一些应用场景的初步探索,可见B端市场大有可为。
B端客群的拓展,则会进一步强化大模型的应用价值,同时形成更为可观的生态效应与集群效应。一者,大模型降低后B端大量企业客户的涌入,将在交互中带来海量行业新数据,加速大模型的优化进程,推动大模型的智能化程度进一步提升。二者,行业越快进入创造实际价值的阶段,理论上就越有利于厂商完善大模型的商业化服务生态,形成更成熟更良性的产业循环。
整体来看,如今业内正在等待并积极推动大模型在应用端的集中爆发。如果不出意外,大模型领域也会和此前诸多从狂飙期迈入洗牌期的风口一样,一步步提高新玩家的准入门槛,并淘汰越来越多的旧玩家,最终形成个别国民级应用分割市场的寡头竞争格局。如今价格战已然打响,淘汰赛自然也已经随之开启。
投稿邮箱:jiujiukejiwang@163.com 详情访问99科技网:http://www.fun99.cn